🔔News
🔥[2025-06-02]: Our paper is now available on arXiv and we welcome citations: CSVQA: A Chinese Multimodal Benchmark for Evaluating STEM Reasoning Capabilities of VLMs
🔥[2025-05-30]: We developed a complete evaluation pipeline, and the implementation details are available on GitHub.
Introduction
Vision-Language Models (VLMs) have achieved remarkable progress in multimodal understanding, yet their scientific reasoning capabilities remain insufficiently evaluated. Existing multimodal benchmarks mainly focus on general image comprehension or text-based reasoning, lacking authentic scientific contexts that require domain-specific knowledge integrated with visual evidence analysis. To address this gap, we introduce CSVQA, a diagnostic multimodal benchmark designed specifically to evaluate scientific reasoning through domain-grounded visual question answering.
Our benchmark comprises 1,378 carefully crafted question-answer pairs across diverse STEM disciplines, each demanding domain knowledge, integration of visual evidence, and higher-order reasoning. Compared to previous benchmarks, CSVQA emphasizes real-world scientific content and complex reasoning tasks.
Additionally, we propose a rigorous evaluation protocol to systematically assess whether model predictions are supported by valid intermediate reasoning steps, based on curated explanations.
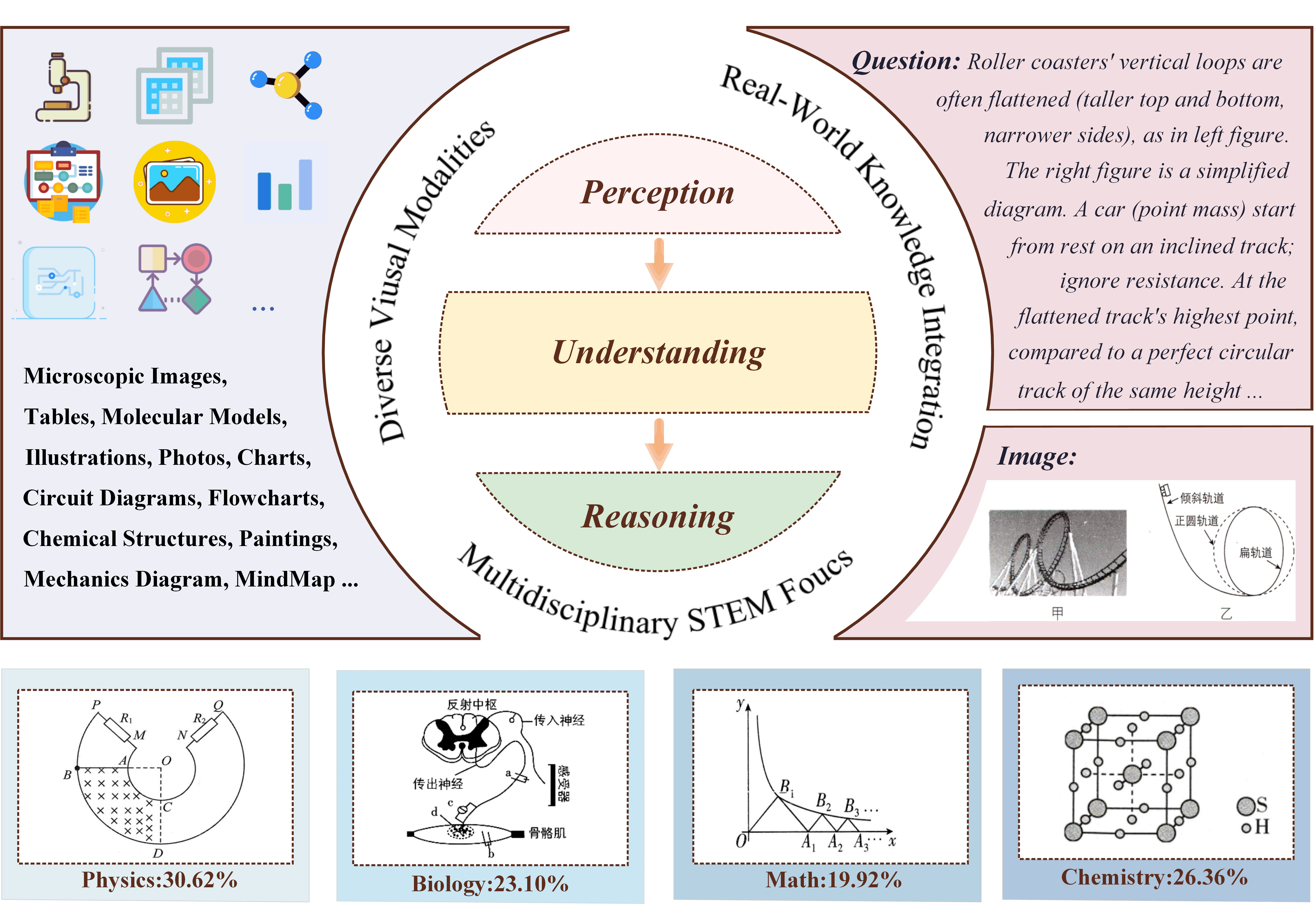
Dataset Source
The dataset is sourced from publicly available Chinese high school textbooks and examination papers across STEM disciplines. To ensure high-quality alignment, we use a four-phase quality control pipeline, improving efficiency over traditional methods.
The process begins by parsing source materials and applying OCR to extract textual and visual data. Then we apply an automated alignment pipeline which is powered by DeepSeekV3 to establish semantic correspondences between questions and answers.
Manual screening then addresses complex cases, such as multi-page layouts and mixed text-image formats. Finally, the benchmark undergoes three independent reviews: schema validation, integrity checks for completeness, and domain-specific audits with the help of annotators to ensure subject accuracy.
From an initial pool of approximately 100,000 raw entries, we filter out unsuitable question types like proof-based or diagram-drawing tasks, discard samples without associated images, and remove mismatched question-answer pairs as flagged by the LLM. A human-curated subset of high-quality multimodal items is retained for the final dataset.
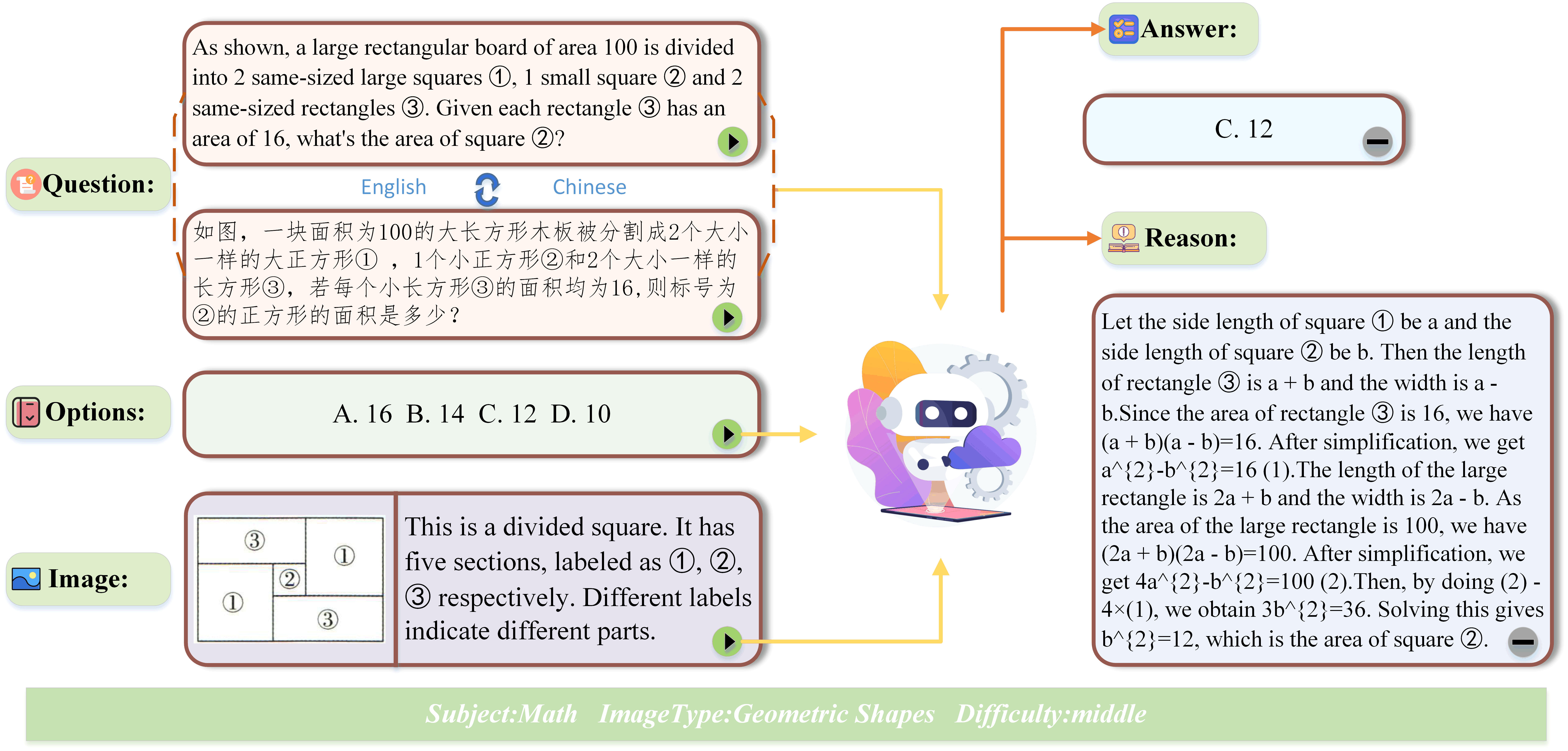
Key Features
First, its coverage of multiple STEM disciplines requires diverse domain knowledge and reasoning strategies. Second, the inclusion of 14 distinct visual modalities introduces significant variation in visual structure and complexity, testing a model’s ability to generalize across image types. Third, many questions are grounded in real-world scenarios and demand domain-specific knowledge, requiring models to go beyond pattern recognition and engage in context-aware reasoning.
An overview of the dataset’s composition is presented in the table below. CSVQA contains 1,378 expert-annotated questions with moderate average length, balancing language processing load and reasoning depth. Nearly 81% of items are paired with a detailed explanation, which is particularly valuable for analyzing logical missteps in model predictions. Furthermore, we incorporated a bilingual dataset generated after translation, allowing for a broader range of test scenarios.
| Statistics | Number |
|---|---|
| Total Questions | 1,378 |
| Image Types | 14 |
| Easy: Medium: Hard | 22.6% : 67.4% : 10.0% |
| Multiple-choice Questions | 1,278 |
| Open Questions | 100 |
| With an Explanation | 81.1% |
| Image in the Question | 1,341 |
| Image in Option | 37 |
| Average Question Length | 69.7 |
| Average Option Length | 12.1 |
| Average Explanation Length | 123.5 |
To better compare with other datasets, the length analysis is conducted in English.